
1.1 — The Three Deployment Models
4 min readThe Three AI Deployment Models
Every AI workload sits in one of three infrastructure categories. Understanding which category you're looking at determines how you measure it, forecast it, optimize it, and govern it.
Model 1 — Closed-Source API (Third-Party)
You call an API. You pay for what you use. You have no access to the model weights, no control over the infrastructure, and no ability to run it anywhere other than the provider's servers.
Examples: OpenAI (GPT-4o, o1, o3), Anthropic (Claude Sonnet, Haiku, Opus), Google (Gemini 2.0 Flash, Gemini 2.5 Pro), Mistral AI.
How billing works: Per token — you pay separately for input tokens (the text you send) and output tokens (the text you receive back). Price is quoted per million tokens. More on this in Section 1.2.
When this model makes economic sense:
- Workloads under roughly 1 million tokens per day
- Teams that need to move fast without managing infrastructure
- Proof-of-concept and early-stage products
- When model quality matters more than cost per token
When it doesn't:
- High-volume, predictable workloads where per-token costs compound quickly
- When data privacy requirements prohibit sending data to third-party endpoints
- When you need to fine-tune or modify the model itself
Model 2 — Third-Party Hosted Open Source
An open-source model (one whose weights are publicly available) running on someone else's managed infrastructure. You still call an API. You still pay per token. But the model is open-source, so the per-token rate is typically lower than closed-source alternatives.
Examples: AWS Bedrock (Llama 3, Mistral, Titan), Azure AI Foundry (Llama, Phi), Google Vertex AI (Llama, Gemma), Together.ai, Groq, Replicate.
How billing works: Same token-based pricing as closed-source APIs, but usually 5–20× cheaper per token for comparable model sizes. Some providers also offer PTUs (Provisioned Throughput Units) — reserved capacity with predictable billing.
When this model makes economic sense:
- Mid-scale workloads: roughly 1 billion to 10 billion tokens per month
- When you want open-source flexibility without managing GPU infrastructure
- When you need predictable pricing via provisioned throughput
- When data residency requirements can be met by choosing specific cloud regions
When it doesn't:
- When volume is high enough that managing your own GPU fleet becomes cheaper
- When you need maximum customization (deeper fine-tuning, model modifications)
Model 3 — Self-Hosted / DIY
You own (or rent long-term) the GPU hardware. You run the model yourself. You manage the infrastructure, the scaling, the uptime, and the MLOps pipeline.
Examples: EC2 p4d/p5 or g5 instances (AWS), A100/H100 VMs (Azure), TPU v4/v5 (Google Cloud), on-premises GPU servers.
How billing works: Fixed capacity cost — instance per hour or reserved instance annual commitment — regardless of how many tokens you process. If your utilization is low, your effective per-token cost skyrockets. If your utilization is high, your effective per-token cost drops dramatically.
When this model makes economic sense:
- Very high volume: above roughly 100 million tokens per day sustained
- When you need to fine-tune models extensively or modify architecture
- When GPU utilization can be maintained above 60–70% continuously
- When data cannot leave your infrastructure under any circumstances
When it doesn't:
- At low to moderate token volumes — the fixed cost makes it far more expensive than pay-as-you-go APIs
- When you don't have an MLOps team to manage the infrastructure
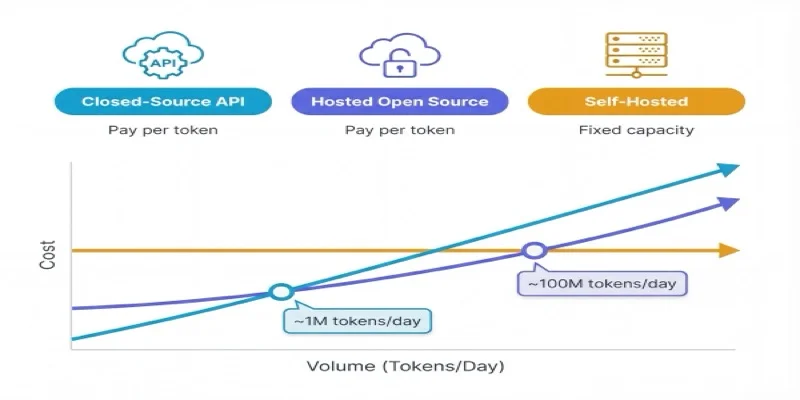
The Economic Crossover
Think of it like car ownership. A taxi (closed-source API) is expensive per mile but has zero fixed cost — perfect if you travel occasionally. A rental car (hosted open-source) is cheaper per mile with moderate commitment. Buying a car (self-hosted) is cheapest per mile but only if you drive enough to justify the fixed cost.
NovaSpark's Team Gamma paid $156K last month for GPUs running at 40% utilization. At that utilization rate, they are in the most expensive quadrant possible — high fixed cost, low volume output. Their effective per-token cost is higher than if they'd just used OpenAI's API.
Key Concepts
Closed-Source API
A third-party hosted model you access via API, paying per token with no access to model weights or infrastructure control.
Third-Party Hosted Open Source
An open-source model running on a cloud provider's managed infrastructure, billed per token at rates typically 5-20x cheaper than closed-source.
Self-Hosted / DIY
You rent or own GPU hardware and run the model yourself, paying a fixed capacity cost regardless of token volume processed.
Economic Crossover
The volume threshold where one deployment model becomes cheaper than another — roughly 1M tokens/day for API vs. hosted, 100M tokens/day for hosted vs. self-hosted.
Choosing an AI Approach and Infrastructure Strategy, FinOps Foundation Working Group — finops.org/wg/choosing-an-ai-approach-and-infrastructure-strategy/
The FinOps for AI exam tests your ability to identify which deployment model is appropriate for a given scenario — not just name them. Know the economic crossover points: roughly 1M tokens/day (API vs. hosted open-source), and roughly 100M tokens/day (hosted vs. self-hosted). Scenarios often involve a team at the wrong model for their volume.