
1.3 — The Context Window Tax
3 min read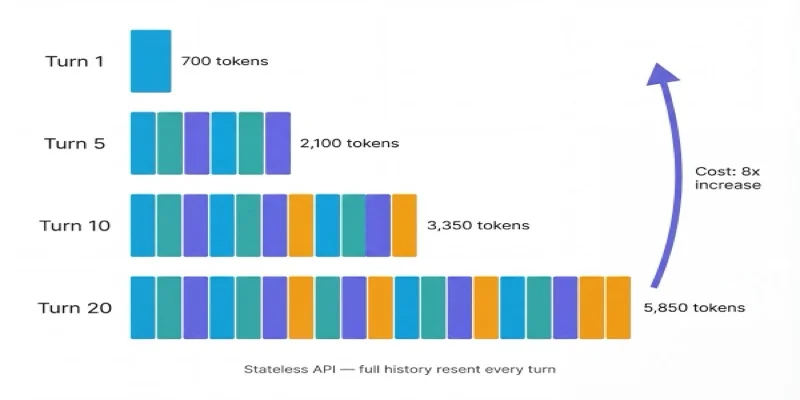
The Context Window Tax
Why APIs Are Stateless
Language models don't have persistent memory between API calls. Each call is completely independent. The model doesn't "remember" that it talked to this user five minutes ago. To create the experience of a continuous conversation, your application code must resend the entire conversation history with every new message.
This is a fundamental architectural reality of how current LLM APIs work. It is not a bug or a limitation that will be patched — it is the design.
The Cost Growth Pattern
Consider a 10-turn customer support conversation. Each turn, the token count grows:
| Turn | New tokens added | Cumulative tokens sent | Cost at GPT-4o |
|---|---|---|---|
| 1 | 100 (user msg) | 700 (system + msg) | $0.0035 |
| 2 | 250 (user + response) | 1,050 | $0.0053 |
| 3 | 250 | 1,400 | $0.0070 |
| 5 | 250 | 2,100 | $0.0105 |
| 10 | 250 | 3,350 | $0.0168 |
| 20 | 250 | 5,850 | $0.0293 |
Turn 20 costs 8× more than Turn 1 — not because the user's message is longer, but because the history is. A customer who has a long back-and-forth with your chatbot costs significantly more to serve than one who resolves their issue in two messages.
What the Context Window Tax Means in Practice
For NovaSpark's chatbot — 180,000 conversations per month, average 8 turns:
- Without context management: average cost ~$0.012/conversation = $2,160/month
- With context trimming (keep last 4 turns): average cost ~$0.007/conversation = $1,260/month
- Savings from one architectural change: $900/month, $10,800/year
For a higher-volume product — 2 million conversations/month:
- Same optimization: $120,000/year in savings
Three Mitigation Approaches
1. Context windowing — Keep only the last N turns of conversation history. Discard older turns. Simple to implement, slight UX risk if conversations reference early context.
2. Summarization compression — Periodically summarize earlier turns into a compact summary, replacing the full transcript. Higher quality retention, moderate implementation complexity.
3. RAG-based memory — Store conversation history externally, retrieve only the semantically relevant parts for each new message. Most sophisticated, best UX, highest implementation cost.
The FinOps Angle
The Context Window Tax is a cost pattern that comes from a product decision (stateful conversation UX), not from infrastructure choices. Engineers building chatbots are making cost decisions every time they choose how much history to include. FinOps practitioners need to work with engineers to surface these cost patterns — not as critique, but as shared visibility. Most engineers building chatbots have never run the compounding math on conversation length.
Key Concepts
Context Window Tax
The compounding cost pattern where each conversation turn resends the entire history, making later turns exponentially more expensive.
Stateless API
LLM APIs have no persistent memory between calls; the full conversation history must be resent with every new message to maintain context.
Context Windowing
A mitigation strategy that keeps only the last N turns of conversation history, discarding older turns to reduce token costs.
Summarization Compression
Periodically summarizing earlier conversation turns into a compact summary to retain context quality while reducing token count.
GenAI FinOps vs. Cloud FinOps, FinOps Foundation Working Group — finops.org/wg/genai-finops-vs-cloud-finops/
The Context Window Tax is tested as a "hidden cost" question and as an optimization scenario. Key facts: APIs are stateless by design; conversation history is resent with every call; cost grows with conversation length, not just volume.