
1.2 — Tokens: The New Unit of Compute
4 min readTokens: The New Unit of Compute
What Is a Token?
A token is the basic unit of text that a language model processes. Not a word — a piece of a word, a word, or sometimes multiple short words together.
A rough rule of thumb: 1 token ≈ 0.75 words in English. More precisely:
- "NovaSpark" → 2 tokens (Nova + Spark)
- "the" → 1 token
- "AI" → 1 token
- "cost" → 1 token
- "optimization" → 4 tokens (optim + ization + ... varies by model)
- A typical business email (300 words) ≈ 400 tokens
- A detailed system prompt (800 words) ≈ 1,066 tokens
- A full legal contract (10,000 words) ≈ 13,333 tokens
Different models tokenize text slightly differently. OpenAI's models use the tiktoken tokenizer. Anthropic's Claude models use a different tokenizer. The 0.75 words-per-token ratio is a useful approximation, not an exact conversion.
Input Tokens vs. Output Tokens
Every API call has two parts:
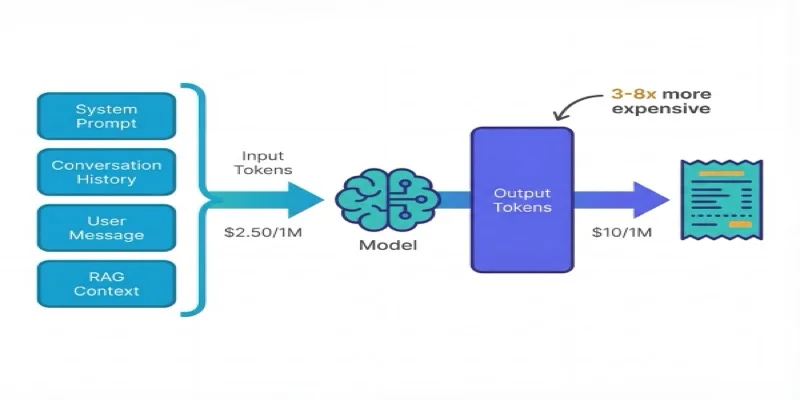
Input tokens — everything you send to the model:
- The system prompt (instructions for how the model should behave)
- The conversation history (all previous messages in a multi-turn chat)
- The current user message
- Any documents or context you've injected (RAG retrieval results, file contents)
Output tokens — everything the model sends back:
- The model's response
This distinction matters because output tokens cost more than input tokens — typically 3× to 8× more, depending on the model.
Why the premium? Generating each output token requires a full forward pass through the model. Reading input tokens is comparatively cheap (the model processes them in parallel). Writing output tokens is sequential — the model generates one token at a time, each dependent on the previous. That sequential computation is why providers charge a premium.
The Token Cost Formula
Cost = (Input Tokens / 1,000,000 × Input Price per 1M)
+ (Output Tokens / 1,000,000 × Output Price per 1M)Current benchmark pricing (February 2026):
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Output/Input ratio |
|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | 4× |
| Claude 3.5 Sonnet | $3.00 | $15.00 | 5× |
| Gemini 2.0 Flash | $0.10 | $0.40 | 4× |
| GPT-4o mini | $0.15 | $0.60 | 4× |
| Claude 3 Haiku | $0.25 | $1.25 | 5× |
| Llama 3.1 70B (Bedrock) | $0.72 | $0.72 | 1× |
| Llama 3.1 8B (Groq) | $0.05 | $0.08 | 1.6× |
Prices change frequently — always verify against provider documentation before forecasting.
A Worked Example
NovaSpark's support chatbot receives a customer message:
- System prompt: 600 tokens
- Conversation history (3 prior turns): 800 tokens
- Current user message: 45 tokens
- Total input: 1,445 tokens
The model responds:
- Response: 220 tokens
- Total output: 220 tokens
At GPT-4o pricing ($2.50 input / $10.00 output per 1M tokens):
Input cost: 1,445 / 1,000,000 × $2.50 = $0.0036
Output cost: 220 / 1,000,000 × $10.00 = $0.0022
Total per call: $0.0058That feels tiny. But NovaSpark's chatbot handles 180,000 conversations per month:
$0.0058 × 180,000 = $1,044/monthNow the product team adds a richer, more detailed system prompt — 2,400 tokens instead of 600:
New input: 2,400 + 800 + 45 = 3,245 tokens
Input cost: 3,245 / 1,000,000 × $2.50 = $0.0081
Output cost unchanged: $0.0022
New total per call: $0.0103
$0.0103 × 180,000 = $1,854/monthAn 800-token system prompt change → $810/month in extra costs. Multiply that across a larger chatbot or a higher-traffic product, and a single engineering commit can add tens of thousands to the monthly bill.
Why This Changes How You Think About Costs
In traditional cloud FinOps, cost scales with infrastructure decisions — instance sizes, storage tiers, network throughput. These are relatively stable and predictable.
In AI FinOps, cost scales with content decisions — what you put in your prompts, how long your conversations are, how verbose your model's responses are. A developer making what looks like a UX change (longer, more helpful responses) is simultaneously making a cost decision. Most developers don't know this yet. Your job is to help bridge that gap.
Key Concepts
Token
The basic unit of text a language model processes, roughly equivalent to 0.75 words in English, and the fundamental billing unit for API-based AI.
Input vs. Output Tokens
Input tokens are what you send to the model; output tokens are what it generates back, costing 3-8x more due to sequential computation.
Token Cost Formula
Cost = (Input Tokens / 1M x Input Price) + (Output Tokens / 1M x Output Price), applied per API call then multiplied by volume.
System Prompt
Instructions sent to the model at the start of every API call; changes to its length multiply across all calls, making it a major hidden cost lever.
GenAI FinOps: How Token Pricing Really Works, FinOps Foundation Working Group — finops.org/wg/genai-finops-how-token-pricing-really-works/
The token cost formula is almost certainly on the exam — both as a direct calculation question and embedded in scenario questions. Memorize: Cost = (Input / 1M × Input price) + (Output / 1M × Output price). Also know why output costs more than input (sequential generation vs. parallel processing).